7 项目 2 - 从头构建 HTTP 服务器
在本章中,我想和你一起实现一个新的小项目。这次,我们将从零开始实现一个基本的 HTTP 服务器。
Zig 标准库已经实现了一个 HTTP 服务器,可在 中找到std.http.Server。但同样,本章的目标是从头开始实现它。因此,我们无法使用 Zig 标准库中提供的这个服务器对象。
7.1什么是 HTTP 服务器?
首先,什么是 HTTP 服务器?HTTP 服务器,和其他类型的服务器一样,本质上是一个无限循环运行的程序,等待来自客户端的连接。一旦服务器收到连接,它就会接受该连接,并通过该连接与客户端来回发送消息。
但是,在此连接内传输的消息具有特定的格式。它们是 HTTP 消息(即使用 HTTP 协议规范的消息)。HTTP 协议是现代网络的支柱。如果没有 HTTP 协议,我们今天所知的万维网将不复存在。
因此,Web 服务器(HTTP 服务器的别称)是与客户端交换 HTTP 消息的服务器。这些 HTTP 服务器和 HTTP 协议规范对于当今万维网的运行至关重要。
这就是整个过程的全貌。同样,这里涉及两个主体:一个服务器(一个无限期运行、等待接收连接的程序)和一个客户端(一个想要连接到服务器并与其交换 HTTP 消息的实体)。
您可以在 Mozilla MDN 文档1中找到有关 HTTP 协议的资料,这也是一个值得一看的优秀资源。它概述了 HTTP 的工作原理以及服务器在其中扮演的角色。
7.2 HTTP 服务器如何工作?
想象一下,HTTP 服务器就像一家大型酒店的接待员。酒店里有一个接待处,接待处里有一位接待员在等待顾客的到来。HTTP 服务器本质上就是一位接待员,它无限期地等待着新顾客(或者,在 HTTP 的语境中,是新客户端)抵达酒店。
当顾客抵达酒店时,他会与接待员交谈。他会告诉接待员他想在酒店住几天。然后,接待员会搜索可用的公寓。如果目前有空房,顾客会支付酒店费用,然后领取公寓钥匙,最后前往公寓休息。
在完成与客户打交道的整个过程(寻找可用的公寓、收到付款、交出钥匙)之后,接待员又回到了他之前的工作——等待。等待新客户的到来。
简而言之,这就是 HTTP 服务器所做的。它等待客户端连接到服务器。当客户端尝试连接服务器时,服务器接受此连接,并开始通过此连接与客户端交换消息。此连接中发生的第一条消息始终是从客户端发送到服务器的消息。此消息称为_HTTP 请求_。
HTTP 请求是一个 HTTP 消息,其中包含客户端希望从服务器获取的信息。它实际上是一个请求。连接到服务器的客户端正在请求服务器为其执行某些操作。
客户端可以向 HTTP 服务器发送不同类型的请求。但最基本的请求类型是客户端请求 HTTP 服务器为其提供(即发送)某个特定的网页(即 HTML 文件)。当您google.com在 Web 浏览器中输入内容时,实际上是在向 Google 的 HTTP 服务器发送 HTTP 请求。该请求要求这些服务器将 Google 网页发送给您。
尽管如此,当服务器收到第一条消息(_HTTP 请求)_时,它会分析此请求,以了解:客户端是谁?他希望服务器执行什么操作?该客户端是否提供了执行其请求操作所需的所有必要信息?等等。
一旦服务器了解了客户端想要什么,它只需执行所请求的操作,然后,为了完成整个过程,服务器会向客户端发送回一个 HTTP 消息,告知所执行的操作是否成功,最后,服务器结束(或关闭)与客户端的连接。
服务器发送给客户端的最后一条 HTTP 消息称为_HTTP 响应_。因为服务器正在响应客户端请求的操作。此响应消息的主要目的是在服务器关闭连接之前,让客户端知道请求的操作是否成功。
7.3 HTTP 服务器通常如何实现?
我们以 C 语言为例。有很多资料教你如何用 C 语言编写一个简单的 HTTP 服务器,比如Yu ( 2023 )、Weerasiri ( 2023 )或Meehan ( 2021 )。考虑到这一点,我不会在这里展示 C 语言代码示例,因为你可以在互联网上找到它们。但我将描述用 C 语言创建此类 HTTP 服务器所需步骤背后的理论。
本质上,我们通常使用 TCP 套接字在 C 中实现 HTTP 服务器,其中包括以下步骤:
- 创建一个 TCP 套接字对象。
- 将名称(或更具体地说,地址)绑定到此套接字对象。
- 使此套接字对象开始监听并等待传入的连接。
- 当连接到达时,我们接受该连接,并交换 HTTP 消息(HTTP 请求和 HTTP 响应)。
- 然后,我们只需关闭这个连接。
套接字对象本质上是一个通信通道。您正在创建一个可供人们发送消息的通道。当您创建套接字对象时,该对象并未绑定到任何特定地址。这意味着,通过该对象,您手中就拥有了一个通信通道的表示。但是,该通道当前不可用,或者说,当前无法访问,因为它没有已知的地址可供您找到。
这就是“绑定”操作的作用。它将一个名称(或者更确切地说,一个地址)绑定到这个套接字对象,或者说,这个通信通道,以便它可用,或者可以通过这个地址访问。而“监听”操作使套接字对象监听这个地址的传入连接。换句话说,“监听”操作使套接字等待传入连接。
现在,当客户端实际尝试通过我们指定的套接字地址连接到服务器时,为了与客户端建立连接,套接字对象需要接受此传入连接。因此,当我们接受传入连接时,客户端和服务器就相互连接了,它们可以开始向这个已建立的连接读取或写入消息。
当我们收到客户端的HTTP请求,分析它,并将HTTP响应发送给客户端后,我们就可以关闭连接,结束本次通信。
7.4实现服务器 - 第一部分
7.4.1创建套接字对象
让我们首先为服务器创建套接字对象。为了简洁起见,我将在一个单独的 Zig 模块中创建这个套接字对象。我将其命名为config.zig。
std.posix.socket()在 Zig 中,我们可以使用Zig 标准库中的函数创建 TCP 套接字。正如我之前在第 7.3 节中提到的,我们创建的每个套接字对象都代表一个通信通道,我们需要将此通道绑定到特定地址。“地址”定义为 IP 地址,或者更具体地说,是 IPv4 地址2。每个 IPv4 地址由两部分组成。第一个部分是主机,它是用点字符 ( .) 分隔的 4 个数字序列,用于标识所使用的机器。第二个部分是端口号,用于标识特定的门,或者主机中要使用的特定端口。
这 4 个数字序列(即主机)标识了套接字所在的机器(即计算机本身)。每台计算机通常内部都有多个“门”,因为这允许计算机同时接收和处理多个连接。它只为每个连接使用一个“门”。因此,端口号本质上是一个数字,用于标识计算机中负责接收连接的特定“门”。也就是说,它标识了套接字将用于接收传入连接的计算机中的“门”。
为了简单起见,我将在此示例中使用标识当前计算机的 IP 地址。这意味着,我们的套接字对象将驻留在我们当前用于编写此 Zig 源代码的同一台计算机上(也称为“localhost”)。
按照惯例,标识“localhost”(即我们当前正在使用的计算机)的 IP 地址是 IP 127.0.0.1。因此,这就是我们将在服务器中使用的 IP 地址。我可以在 Zig 中使用一个包含 4 个整数的数组来声明它,如下所示:
const localhost = [4]u8{ 127, 0, 0, 1 };
_ = localhost;
现在,我们需要决定使用哪个端口号。按照惯例,有些端口号是保留的,这意味着我们不能将它们用于自己的目的,例如端口 22(通常用于 SSH 连接)。对于 TCP 连接(此处为示例),端口号是一个 16 位无符号整数(u16以 Zig 格式输入),范围从 0 到 65535 (维基百科 2024)。因此,我们可以从 0 到 65535 中选择一个数字作为端口号。在本书的示例中,我将使用端口号 3490(只是一个随机数)。
现在我们掌握了这两个信息,终于可以使用std.posix.socket()函数创建套接字对象了。首先,我们使用主机名和端口号,Address通过std.net.Address.initIp4()函数创建一个对象,如下例所示。然后,我在socket()函数内部使用这个地址对象来创建套接字对象。
下面定义的结构体Socket概括了此过程背后的所有逻辑。在这个结构体中,我们有两个数据成员:1)地址对象;2)流对象,我们将使用该对象在建立的任何连接中读取和写入消息。
请注意,在此结构的构造函数方法中,当我们创建套接字对象时,我们使用该IPROTO.TCP属性作为输入来告诉函数为 TCP 连接创建套接字。
const std = @import("std");
const builtin = @import("builtin");
const net = @import("std").net;
pub const Socket = struct {
_address: std.net.Address,
_stream: std.net.Stream,
pub fn init() !Socket {
const host = [4]u8{ 127, 0, 0, 1 };
const port = 3490;
const addr = net.Address.initIp4(host, port);
const socket = try std.posix.socket(
addr.any.family,
std.posix.SOCK.STREAM,
std.posix.IPPROTO.TCP
);
const stream = net.Stream{ .handle = socket };
return Socket{ ._address = addr, ._stream = stream };
}
};
7.4.2监听和接收连接
记住,我们将在7.4.1 节Socket中构建的结构声明存储在名为 的 Zig 模块中。这就是为什么在下面的示例中,我将这个模块作为对象导入到我们的主模块 ( ) 中,以访问该结构。config.zig``main.zig``SocketConf``Socket
创建完套接字对象后,我们现在可以专注于让该套接字对象监听并接收新的连接。具体操作如下:调用套接字对象内部listen()的方法Address,然后对accept()结果调用该方法。
listen()该对象的方法会Address生成一个服务器对象,该对象将保持打开状态并无限期运行,等待接收传入的连接。因此,如果您尝试通过调用编译器run中的命令来运行下面的代码示例zig,您会注意到程序会无限期地运行,没有明确的结束。
发生这种情况是因为程序正在等待某些事情发生。它正在等待某人尝试连接到http://127.0.0.1:3490服务器正在运行并监听传入连接的地址 ( )。这就是该listen()方法的作用,它使套接字处于活动状态,等待某人连接。
另一方面,该accept()方法是当有人尝试连接到套接字时建立连接的函数。这意味着该accept()方法会返回一个新的连接对象。您可以使用此连接对象从客户端读取或写入消息。目前,我们不会使用此连接对象执行任何操作。但我们将在下一节中使用它。
const std = @import("std");
const SocketConf = @import("config.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
_ = connection;
}
此代码示例只允许一个连接。换句话说,服务器将等待一个传入连接,一旦服务器处理完它建立的第一个连接,程序就会结束,服务器也会停止运行。
这在现实世界中并不常见。大多数编写此类 HTTP 服务器的人通常会将该accept()方法放在一个while(无限)循环中,如果使用 创建一个连接accept(),就会创建一个新的执行线程来处理这个新连接和客户端。也就是说,现实世界中的 HTTP 服务器示例通常依赖于并行计算来工作。
通过这种设计,服务器只需接受连接,而处理客户端、接收 HTTP 请求和发送 HTTP 响应的整个过程都在后台的单独执行线程中完成。
因此,一旦服务器接受连接并创建单独的线程,服务器就会回到之前的操作,即无限期地等待新的连接接受。考虑到这一点,上面展示的代码示例是一个仅服务于单个客户端的服务器。因为程序在连接接受后立即终止。
7.4.3读取客户端的消息
现在我们已经建立了连接,也就是通过accept()函数创建的连接对象,我们可以用这个连接对象读取客户端发送给服务器的任何消息。当然,我们也可以用它来将消息发回给客户端。
基本思路是,如果我们向这个连接对象写入任何数据,那么我们就是在向客户端发送数据;如果我们读取这个连接对象中的数据,那么我们就是在读取客户端通过这个连接对象发送给我们的任何数据。所以,记住这个逻辑就行了。“读取”表示从客户端读取消息,“写入”表示向客户端发送消息。
还记得7.2 节中提到过,我们需要做的第一件事就是读取客户端发送给服务器的 HTTP 请求。因为这是建立连接后发生的第一条消息,因此,也是我们需要处理的第一件事。
因此,我将在这个小项目中创建一个新的 Zig 模块,命名为 ,request.zig以便将所有与 HTTP 请求相关的函数集中在一起。然后,我将创建一个名为 的新函数read_request(),它将使用我们的连接对象读取客户端发送的消息,即 HTTP 请求。
const std = @import("std");
const Connection = std.net.Server.Connection;
pub fn read_request(conn: Connection,
buffer: []u8) !void {
const reader = conn.stream.reader();
_ = try reader.read(buffer);
}
此函数接受一个充当缓冲区的切片对象作为参数。该read_request()函数读取发送到连接对象的消息,并将该消息保存到我们作为输入提供的缓冲区对象中。
请注意,我使用我们创建的连接对象来读取来自客户端的消息。我首先访问reader连接对象内部的对象。然后,我调用read()该reader对象的方法,有效地读取客户端发送的数据并将其保存到我们之前创建的缓冲区对象中。我丢弃了该read()方法的返回值,并将其赋值给下划线字符 ( _),因为这个返回值目前对我们没什么用。
7.5查看程序的当前状态
我想现在是时候看看我们的程序目前运行情况了。好吗?所以,我要做的第一件事是更新main.zig我们小型 Zig 项目中的模块,以便main()函数调用read_request()我们刚刚创建的新函数。我还会在函数末尾添加一个打印语句main(),这样你就能看到我们刚刚加载到缓冲区对象中的 HTTP 请求是什么样子的。
另外,我在函数中创建了缓冲区对象main(),该对象将负责存储客户端发送的消息,并且我还使用for循环将此缓冲区对象的所有字段初始化为零。这一点很重要,以确保此对象中没有未初始化的内存。因为未初始化的内存可能会导致程序中出现未定义的行为。
由于该read_request()函数应该将缓冲区对象作为切片对象([]u8)接收作为输入,因此我使用语法array[0..array.len]来访问该buffer对象的切片。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
_ = try Request.read_request(
connection, buffer[0..buffer.len]
);
try stdout.print("{s}\n", .{buffer});
}
现在,我将使用编译器run的命令来执行这个程序zig。但请记住,正如我们之前提到的,一旦我执行这个程序,它就会无限期地挂起,因为它正在等待客户端尝试连接到服务器。
更具体地说,程序会在调用该accept()函数的那一行暂停。一旦客户端尝试连接服务器,程序就会“恢复暂停”,accept()最终执行该函数来创建我们需要的连接对象,然后程序的剩余部分将继续运行。
您可以在图 7.1中看到。消息Server Addr: 127.0.0.1:3490已打印到控制台,程序现在正在等待传入连接。
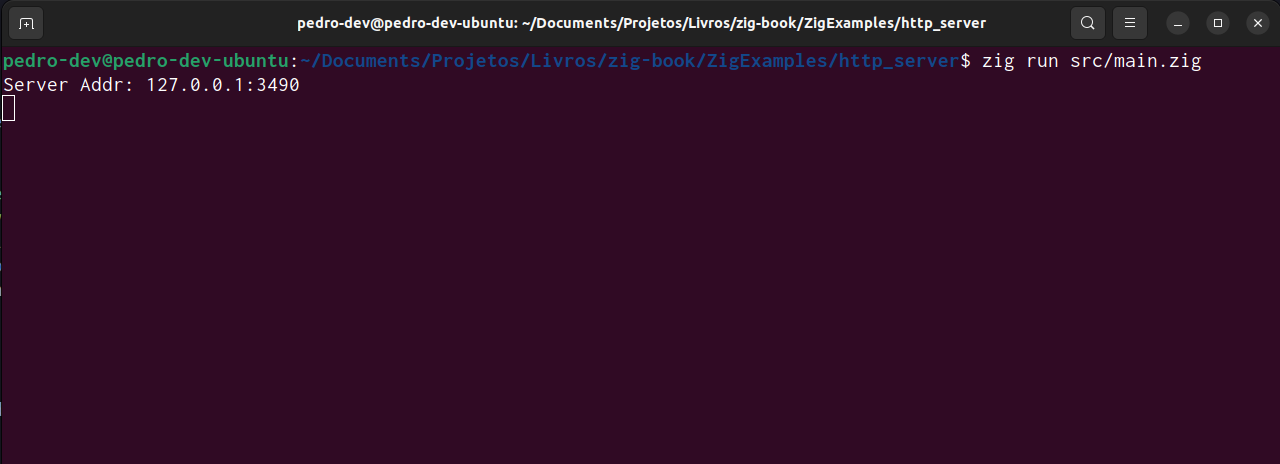
图7.1:程序运行截图
我们终于可以尝试连接到该服务器了,有几种方法可以做到这一点。例如,我们可以使用以下 Python 脚本:
import requests
requests.get("http://127.0.0.1:3490")
或者,我们也可以打开任何我们喜欢的 Web 浏览器,然后输入 URL localhost:3490。OBS:localhost与 IP 相同127.0.0.1。当您按下 Enter 键,Web 浏览器转到此地址时,首先,浏览器可能会打印一条消息,提示“此页面无法正常工作”,然后,它可能会更改为一条新消息,提示“无法访问该网站”。
您在 Web 浏览器中看到这些“错误消息”,是因为它没有收到服务器的响应。换句话说,当 Web 浏览器连接到我们的服务器时,它确实通过已建立的连接发送了 HTTP 请求。然后,Web 浏览器期望收到 HTTP 响应,但却没有收到服务器的响应(我们尚未实现 HTTP 响应逻辑)。
但这没关系。我们已经实现了目前想要的结果,即连接到服务器,并查看 Web 浏览器(或 Python 脚本)向服务器发送的 HTTP 请求。
如果您在执行程序后返回到之前打开的控制台,您将看到程序已完成执行,并且控制台中打印了一条新消息,这是 Web 浏览器向服务器发送的实际 HTTP 请求消息。您可以在图 7.2中看到此消息。
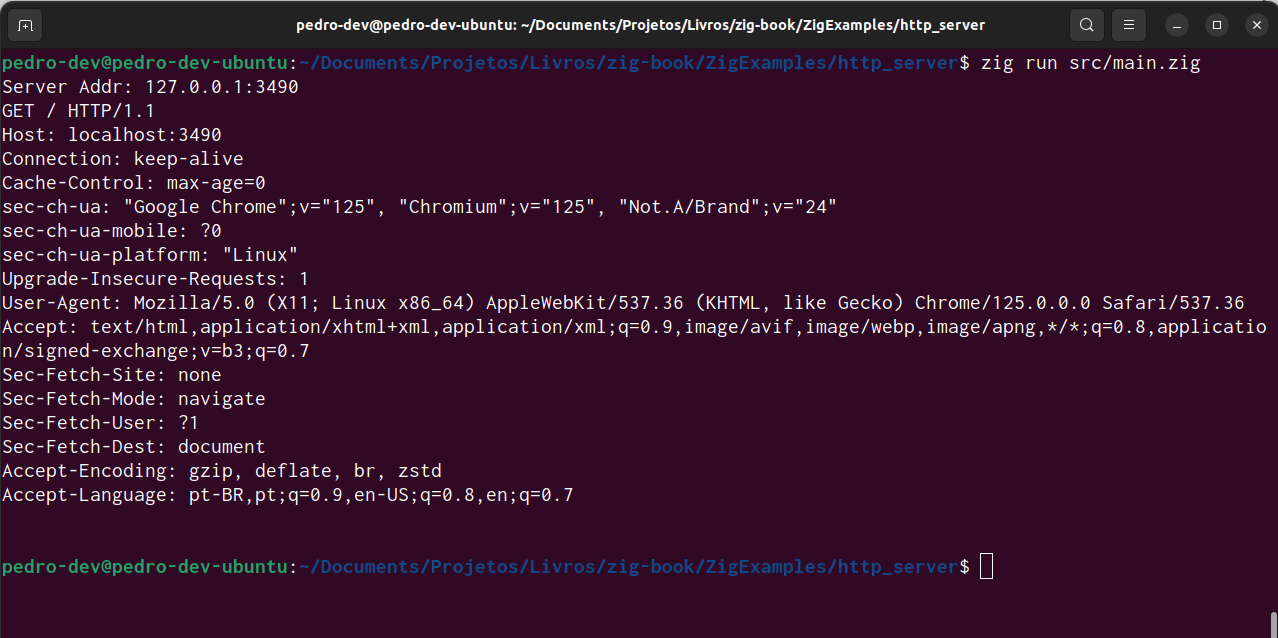
图 7.2:Web 浏览器发送的 HTTP 请求的屏幕截图
7.6了解 Zig 中的枚举
在 Zig 中,枚举结构可以通过enum关键字使用。枚举(“enumeration” 的缩写)是一种表示一组常量值的特殊结构。因此,如果您有一个变量可以假设一组简短且已知的值,则可能需要将此变量与枚举结构关联,以确保此变量仅假设该集合中的值。
枚举的一个经典示例是原色。如果出于某种原因,你的程序需要表示一种原色,你可以创建一个表示其中一种颜色的枚举。在下面的例子中,我们创建了一个枚举PrimaryColorRGB,它表示 RGB 颜色系统中的一种原色。通过使用此枚举,我可以保证对象acolor将包含以下三个值之一:RED、GREEN或BLUE。
const PrimaryColorRGB = enum {
RED, GREEN, BLUE
};
const acolor = PrimaryColorRGB.RED;
_ = acolor;
如果出于某种原因,我的代码尝试将acolor一个不在该集合中的值保存到 中,我会收到一条错误消息,警告我枚举中不存在诸如“MAGENTA”之类的值PrimaryColorRGB。这样我就可以轻松地修复我的错误。
const acolor = PrimaryColorRGB.MAGENTA;
e1.zig:5:36: error: enum 'PrimaryColorRGB' has
no member named 'MAGENTA':
const acolor = PrimaryColorRGB.MAGENTA;
^~~~~~~
在底层,Zig 中的枚举的工作方式与 C 语言中的枚举相同。每个枚举值本质上都表示为一个整数。集合中的第一个值表示为零,然后第二个值表示为一,……等等。
下一节我们将学习的一件事是枚举中可以包含方法。等等……什么?这太神奇了!是的,Zig 中的枚举类似于结构体,它们内部可以包含私有方法和公共方法。
7.7实现服务器 - 第 2 部分
现在,在本节中,我将重点介绍如何解析从客户端收到的 HTTP 请求。但是,为了有效地解析 HTTP 请求消息,我们首先需要了解其结构。总而言之,HTTP 请求是一条文本消息,它分为三个不同的部分(或部分):
- 顶级标头指示 HTTP 请求的方法、URI 和消息中使用的 HTTP 版本。
- HTTP 标头列表。
- HTTP 请求的主体。
7.7.1顶级标题
HTTP 请求的第一行文本总是包含有关该请求的三个最重要的信息。这三个关键属性在请求的第一行中用一个空格分隔。第一行信息是请求中使用的 HTTP 方法;第二行是此 HTTP 请求的目标 URI;第三行是此 HTTP 请求中使用的 HTTP 协议版本。
在下面的代码片段中,您可以找到 HTTP 请求中第一行的示例。首先,我们有此请求的 HTTP 方法(GET)。许多程序员将 URI 组件(/users/list)称为 HTTP 请求要发送到的“API 端点”。在这个特定请求的上下文中,由于它是一个 GET 请求,您也可以说 URI 组件是我们要访问的资源的路径,或者,是我们想要从服务器检索的文档(或文件)的路径。
GET /users/list HTTP/1.1
另外,请注意,此 HTTP 请求使用的是 HTTP 协议 1.1 版本,这是 Web 上使用的最流行的协议版本。
7.7.2 HTTP 标头列表
大多数 HTTP 请求还包含一段 HTTP 标头,其中包含与该特定请求关联的属性或键值对的列表。此部分始终位于请求的“顶级标头”之后。
本章的目标是构建一个简单的 HTTP 服务器,为了简单起见,我们将忽略 HTTP 请求的这一部分。但大多数现有的 HTTP 服务器都会解析并使用这些 HTTP 标头来更改服务器响应客户端请求的方式。
例如,我们在现实世界中遇到的许多请求都带有一个名为 的 HTTP 标头Accept。在此标头中,我们可以找到一个MIME 类型3的列表。此列表指示客户端可以读取、解析或解释的文件格式。换句话说,您也可以将此标头解释为客户端向服务器发出以下信息:“嘿!看,我只能读取 HTML 文档,所以请给我发送一个 HTML 格式的文档。”
如果 HTTP 服务器能够读取并使用此Accept标头,那么它就能识别出发送给客户端的文档的最佳文件格式。HTTP 服务器可能拥有同一份文档的多种格式,例如 JSON、XML、HTML 和 PDF,但客户端只能理解 HTML 格式的文档。这就是此标头的作用Accept。
7.7.3正文
正文位于 HTTP 标头列表之后,是 HTTP 请求的可选部分,这意味着并非所有 HTTP 请求都会包含正文。例如,使用 GET 方法的 HTTP 请求通常不包含正文。
因为 GET 请求用于请求数据,而不是将其发送到服务器。因此,主体部分与 POST 方法更相关,后者是一种涉及将数据发送到服务器进行处理和存储的方法。
由于我们将在此项目中仅支持 GET 方法,这意味着我们也不需要关心请求的主体。
7.7.4创建 HTTP 方法枚举
每个 HTTP 请求都带有一个显式的方法。HTTP 请求中使用的方法由以下单词之一标识:
- 得到;
- 邮政;
- 选项;
- 修补;
- 删除;
- 以及其他一些方法。
每种 HTTP 方法都用于特定类型的任务。例如,POST 方法通常用于将一些数据发送到目标。换句话说,它用于将一些数据发送到 HTTP 服务器,以便服务器处理和存储这些数据。
再举一个例子,GET 方法通常用于从服务器获取内容。换句话说,每当我们希望服务器返回一些内容时,我们都会使用此方法。返回的内容可以是任何类型的内容,可以是网页、文档文件,也可以是 JSON 格式的数据。
当客户端发送 POST HTTP 请求时,服务器发送的 HTTP 响应通常只有一个目的,那就是告知客户端服务器是否成功处理并存储了数据。相反,当服务器收到 GET HTTP 请求时,它会在 HTTP 响应中发送客户端请求的内容。这表明,与 HTTP 请求相关的方法会极大地改变整个过程中各方的动态和角色。
由于 HTTP 请求的 HTTP 方法由这组非常小且特定的单词标识,因此创建一个枚举结构来表示 HTTP 方法将会很有趣。这样,我们可以轻松检查从客户端收到的 HTTP 请求是否是我们当前在小型 HTTP 服务器项目中支持的 HTTP 方法。
下面的结构Method代表了这个枚举。请注意,目前,此枚举仅包含 GET HTTP 方法。因为就本章而言,我只想实现 GET HTTP 方法。这就是为什么我没有在此枚举中包含其他 HTTP 方法的原因。
pub const Method = enum {
GET
};
现在,我认为我们应该为这个枚举结构添加两个方法。一个方法是is_supported(),它是一个返回布尔值的函数,指示我们的 HTTP 服务器是否支持输入的 HTTP 方法。另一个方法是init(),它是一个构造函数,它接受一个字符串作为输入,并尝试将其转换为一个Method值。
但是为了构建这些函数,我将使用 Zig 标准库中的一项功能StaticStringMap()。此函数允许我们创建一个从字符串到枚举值的简单映射。换句话说,我们可以使用此映射结构将字符串映射到相应的枚举值。在某种程度上,标准库中的这个特定结构的工作原理几乎类似于“哈希表”结构,并且它针对较小的单词集或较小的键集进行了优化,这就是我们这里的情况。我们将在第 11.2 节中详细讨论 Zig 中的哈希表。
要使用这个“静态字符串映射”结构,必须从std.static_string_mapZig 标准库的模块中导入它。为了使代码更简洁、更容易输入,我将使用一个更短的名称 ( Map) 来导入此函数。
导入后Map(),我们可以将此函数应用于将在结果映射中使用的枚举结构。在本例中,它是我们在上一个代码示例中声明的枚举结构。然后,我使用映射(即我们将要使用的键值对列表)Method调用该方法。initComptime()
您可以在下面的示例中看到,我使用多个匿名结构体字面量编写了这个映射。在第一个(或“顶层”)结构体字面量中,我们有一个结构体字面量的列表(或序列)。此列表中的每个结构体字面量代表一个单独的键值对。每个键值对中的第一个元素(或键)应始终为字符串值。而第二个元素应为Map()函数内部使用的枚举结构中的值。
const Map = std.static_string_map.StaticStringMap;
const MethodMap = Map(Method).initComptime(.{
.{ "GET", Method.GET },
});
因此,该MethodMap对象本质上是std::mapC++ 中的对象,或者Python 中的对象。您可以使用map 对象中的方法dict检索(或获取)与特定键对应的枚举值。此方法返回一个可选值,因此该方法可能导致空值。get()``get()
我们可以利用这一点来检测我们的 HTTP 服务器是否支持某个特定的 HTTP 方法。因为,如果该get()方法返回 null,则意味着它没有找到我们在对象内部提供的方法MethodMap,因此,我们的 HTTP 服务器不支持该方法。
下面的方法init()接受一个字符串值作为输入,然后简单地将该字符串值传递给get()我们MethodMap对象的方法。结果,我们应该得到与该输入字符串对应的枚举值。
请注意,在下面的示例中,该init()方法要么返回错误(如果?方法返回unreacheable,则可能发生这种情况,有关更多详细信息,请参阅6.4.3 节Method),要么返回一个对象作为结果。由于GET当前是枚举结构中的唯一值Method,这意味着该init()方法很可能会返回该值Method.GET作为结果。
还要注意,在该方法中,我们使用了该方法is_supported()从对象返回的可选值。 if 语句会解开此方法返回的可选值,如果该可选值非空,则返回 。否则,它直接返回。get()``MethodMap``true``false
pub const Method = enum {
GET,
pub fn init(text: []const u8) !Method {
return MethodMap.get(text).?;
}
pub fn is_supported(m: []const u8) bool {
const method = MethodMap.get(m);
if (method) |_| {
return true;
}
return false;
}
};
7.7.5编写解析请求函数
现在我们创建了代表 HTTP 方法的枚举,我们应该开始编写负责实际解析 HTTP 请求的函数。
我们能做的第一件事是编写一个结构体来表示 HTTP 请求。以Request下面这个结构体为例,它包含了 HTTP 请求中“顶级”头部(即第一行)的三个基本信息。
const Request = struct {
method: Method,
version: []const u8,
uri: []const u8,
pub fn init(method: Method,
uri: []const u8,
version: []const u8) Request {
return Request{
.method = method,
.uri = uri,
.version = version,
};
}
};
该parse_request()函数应该接收一个字符串作为输入。此输入字符串包含完整的 HTTP 请求消息,解析函数应该读取并理解该消息的各个部分。
现在,请记住,就本章的目的而言,我们只关心此消息的第一行,其中包含“顶级标头”,或者有关 HTTP 请求的三个基本属性,即使用的 HTTP 方法、URI 和 HTTP 版本。
indexOfScalar()请注意,我使用了中的函数parse_request()。这个来自 Zig 标准库的函数返回我们提供的标量值在字符串中出现的第一个索引。在本例中,我查看的是换行符 ( \n) 的第一次出现。因为再次强调,我们只关心 HTTP 请求消息中的第一行。这一行包含了我们要解析的三个信息(HTTP 版本、HTTP 方法和 URI)。
因此,我们使用此indexOfScalar()函数将解析过程限制在消息的第一行。另外值得一提的是,该indexOfScalar()函数返回一个可选值。因此,我使用orelse关键字来提供替代值,以防函数返回的值为空。
由于这三个属性都由一个简单的空格分隔,我们可以使用splitScalar()Zig 标准库中的函数,通过查找出现简单空格的每个位置,将输入字符串拆分成多个部分。换句话说,这个splitScalar()函数相当于split()Python 中的方法,或者std::getline()C++ 中的函数,或者strtok()C 中的函数。
使用此splitScalar()函数时,您将获得一个迭代器作为结果。此迭代器具有一个next()方法,您可以使用该方法将迭代器推进到下一个位置,或者推进到分割字符串的下一部分。请注意,当您使用 时next(),该方法不仅会推进迭代器,还会返回分割字符串当前部分的切片作为结果。
现在,如果您想要获取拆分字符串当前部分的切片,但不将迭代器推进到下一个位置,则可以使用peek()方法。next()和peek()方法都返回一个可选值,因此我使用?方法来解包这些可选值。
pub fn parse_request(text: []u8) Request {
const line_index = std.mem.indexOfScalar(
u8, text, '\n'
) orelse text.len;
var iterator = std.mem.splitScalar(
u8, text[0..line_index], ' '
);
const method = try Method.init(iterator.next().?);
const uri = iterator.next().?;
const version = iterator.next().?;
const request = Request.init(method, uri, version);
return request;
}
正如我在第 1.8 节中所述,Zig 中的字符串只是语言中的字节数组。因此,您将在 Zig 标准库中找到许多可直接在此模块中使用字符串的优秀实用函数。我们已经在1.8.5 节mem中描述了其中一些有用的实用函数。
7.7.6使用解析请求函数
现在我们编写了负责解析 HTTP 请求的函数,我们可以在程序的函数parse_request()中添加函数调用。main()
之后,最好再测试一下程序的状态。我用编译器run的命令再次执行这个程序zig,然后,我用浏览器通过 URL 再次连接到服务器localhost:3490,最后,将Request对象的最终结果打印到控制台上。
快速观察一下,由于我在打印语句中使用了格式说明符,因此结构体的any数据成员version和被打印为原始整数值。在 Zig 中,将字符串数据打印为整数值很常见,请记住,这些整数值只是构成相关字符串的字节的十进制表示。uri``Request
在下面的结果中,十进制值序列 72、84、84、80、47、49、46、49 和 13 是构成文本“HTTP/1.1”的字节。整数 47 是字符 的十进制值/,它代表了此请求中的 URI。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
try Request.read_request(
connection, buffer[0..buffer.len]
);
const request = Request.parse_request(
buffer[0..buffer.len]
);
try stdout.print("{any}\n", .{request});
}
request.Request{
.method = request.Method.GET,
.version = {72, 84, 84, 80, 47, 49, 46, 49, 13},
.uri = {47}
}
7.7.7向客户端发送 HTTP 响应
在最后一部分,我们将编写负责从服务器向客户端发送 HTTP 响应的逻辑。为了简单起见,本项目中的服务器将只发送一个包含文本“Hello world”的简单网页。
首先,我在项目中创建一个名为 的新 Zig 模块response.zig。在此模块中,我将仅声明两个函数。每个函数对应于 HTTP 响应中的特定状态代码。send_200()函数将向客户端发送状态代码为 200(表示“成功”)的 HTTP 响应。 函数将send_404()发送状态代码为 404(表示“未找到”)的响应。
这绝对不是处理 HTTP 响应最符合人体工程学且最合适的方法,但它适用于我们这里的情况。毕竟,本书只是在构建一些小项目,因此,我们编写的源代码不需要完美。它只要能正常工作就行!
const std = @import("std");
const Connection = std.net.Server.Connection;
pub fn send_200(conn: Connection) !void {
const message = (
"HTTP/1.1 200 OK\nContent-Length: 48"
++ "\nContent-Type: text/html\n"
++ "Connection: Closed\n\n<html><body>"
++ "<h1>Hello, World!</h1></body></html>"
);
_ = try conn.stream.write(message);
}
pub fn send_404(conn: Connection) !void {
const message = (
"HTTP/1.1 404 Not Found\nContent-Length: 50"
++ "\nContent-Type: text/html\n"
++ "Connection: Closed\n\n<html><body>"
++ "<h1>File not found!</h1></body></html>"
);
_ = try conn.stream.write(message);
}
需要注意的是,这两个函数都接收连接对象作为输入,并使用该write()方法将 HTTP 响应消息直接写入此通信通道。这样,连接的另一端(即客户端)就会收到该消息。
大多数实际的 HTTP 服务器都会有一个单独的函数(或单独的结构体)来有效地处理响应。它获取已解析的 HTTP 请求作为输入,然后尝试逐位构建 HTTP 响应,最后通过连接发送。
我们还将使用一个专门的结构体来表示 HTTP 响应,以及许多用于构建响应对象各个部分或组件的方法。Response以 JavaScript 运行时 Bun 创建的结构体为例。您可以在其 GitHub 项目的response.zig模块4中找到此结构体。
7.8最终结果
现在,我们可以再次更新我们的main()函数,以合并模块中的新函数response.zig。首先,我需要将此模块导入到我们的main.zig模块中,然后,我将函数调用添加到send_200()和send_404()。
请注意,我使用了 if 语句来决定调用哪个“响应函数”,特别是基于 HTTP 请求中的 URI。如果用户请求的内容(或文档)不存在于我们的服务器中,我们应该返回 404 状态码。但由于我们只有一个简单的 HTTP 服务器,没有实际的文档需要发送,因此我们只需检查 URI 是否为根路径 ( /) 即可决定调用哪个函数。
另外,请注意,我正在使用 Zig 标准库中的函数std.mem.eql()来检查字符串 from 是否uri等于字符串。我们已经在1.8.5 节"/"中描述了这个函数,所以如果您还不熟悉这个函数,请回到该节。
const std = @import("std");
const SocketConf = @import("config.zig");
const Request = @import("request.zig");
const Response = @import("response.zig");
const Method = Request.Method;
const stdout = std.io.getStdOut().writer();
pub fn main() !void {
const socket = try SocketConf.Socket.init();
try stdout.print("Server Addr: {any}\n", .{socket._address});
var server = try socket._address.listen(.{});
const connection = try server.accept();
var buffer: [1000]u8 = undefined;
for (0..buffer.len) |i| {
buffer[i] = 0;
}
try Request.read_request(connection, buffer[0..buffer.len]);
const request = Request.parse_request(
buffer[0..buffer.len]
);
if (request.method == Method.GET) {
if (std.mem.eql(u8, request.uri, "/")) {
try Response.send_200(connection);
} else {
try Response.send_404(connection);
}
}
}
现在我们已经调整了函数,现在可以执行程序,看看这些最后修改的效果了。首先,我使用编译器的命令main()再次执行程序。程序会挂起,等待客户端连接。run``zig
然后,我打开 Web 浏览器,尝试使用 URL 再次连接到服务器localhost:3490。这一次,浏览器不会显示任何错误消息,而是会打印出“Hello World”消息。因为这一次,服务器成功地向 Web 浏览器发送了 HTTP 响应,如图7.3 所示。
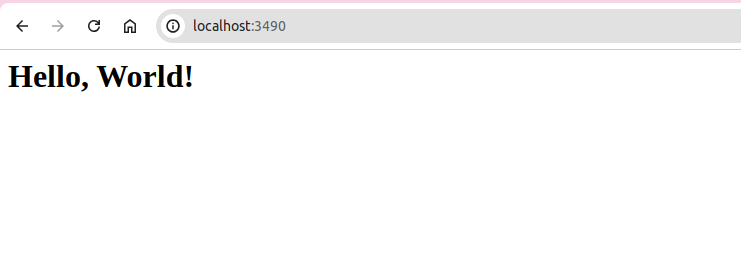
图 7.3:HTTP 响应中发送的 Hello World 消息